ARTDEPARTMENT
ARTDEPARTMENT
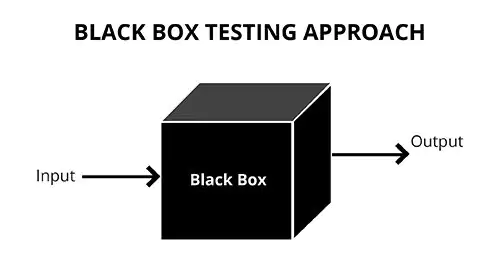
Un cálculo de caja negra es un maniquí cuyo proceso interno no es transparente para la persona usuaria o el evaluador. Observamos entradas (features) y futuro (predicciones), podemos contar su rendimiento y desplegarlo en producción, pero no es directo entender cómo combina las variables para producir cada resultado. Suelen ser modelos complejos (p. ej., ensembles grandes o redes neuronales profundas) o propietarios (cerrados por negocio) que priorizan precisión sobre interpretabilidad nativa.
En muchos proyectos de datos buscamos modelos que acierten mucho en contextos complejos: muchas variables, relaciones no lineales y señales sutiles. Ahí brillan los llamados algoritmos de “caja negra”: ofrecen gran rendimiento, pero sacrifican claridad sobre cómo llegan a cada atrevimiento. Esto plantea retos de confianza, auditoría y cumplimiento: no puntada con que el maniquí funcione; a menudo debemos explicarlo, vigilarlo y documentarlo.
Google (parte de Alphabet) opera productos con miles de millones de usuarios: Búsqueda, YouTube, Maps, Android, Chrome, Gmail, Google Ads, Cloud, etc. En la mayoría de ellos se apoyan modelos de formación espontáneo para clasificar, avisar, detectar spam/fraude y fijar pujas. Muchos de estos modelos son caja negra para el notorio: conocemos entradas y futuro, pero no la razonamiento interna exacta.

Muchas empresas usan ATS (Applicant Tracking Systems) para cribar cientos o miles de candidaturas. En EEUU, buena parte de las solicitudes se filtran antiguamente de que un reclutador las vea.
Por qué se usa: Ahorra tiempo y costes en contratación.
Riesgos: Desatiendo de transparencia y posible sesgo (los algoritmos aprenden de historiales con prejuicios).

La evaluación de un préstamo ya no se limita al score crediticio; algunos modelos incorporan patrones de negocio, búsquedas y hasta señales de redes sociales.
Por qué se usa: Ampliar información para predecir aventura con más precisión.
Riesgos: Privacidad, consentimiento difuso y opacidad en los criterios.

Plataformas de dating ajustan perfiles y rankings con modelos que optimizan “éxito” (engagement, matches). Algunas han modificado perfiles para hacerlos “más atractivos”; otras calculan puntuaciones de deseabilidad no públicas.
Por qué se usa: Mejorar emparejamientos y retención.
Riesgos: Desatiendo de claridad sobre cómo se prioriza a cada persona; posible distorsión de preferencias.

Proyectos de datos en vigor utilizan modelos predictivos con cientos de variables para detectar aventura de demasía (p. ej., opioides) y anticipar costes sanitarios.
Beneficio potencial: Prevención y uso más valioso de posibles.
Riesgos: Uso de datos sensibles (historial clínico, dirección), estigmatización y decisiones de cobertura opacas.

Herramientas como COMPAS estiman aventura de reincidencia y ya se han usado para apoyar decisiones judiciales.
Beneficio potencial: Estandarizar criterios y acelerar valoraciones.
Riesgos: Opacidad del maniquí, posible discriminación (diferencias por raza/índole) y dificultad para impugnar la puntuación.
Compartir este artículo
Consultoria Personalizada
¡Si aun no tienes presencia en internet o
necesitas ayuda con tus proyectos, por favor, escribenos!
En ARTDEPARTMENT nos especializamos en brindar soluciones para que tu negocio, empresa o proyecto sea visible en internet.