ARTDEPARTMENT
ARTDEPARTMENT

Parece que fue ayer y ya hace más de dos primaveras que OpenAI lanzó ChatGPT para todo el mundo marcando un antaño y un luego en la tecnología. Y eso es solo el principio: la meta de OpenAI es conseguir la Inteligencia Industrial Genérico o AGI y ya están muy cerca de lograrlo, o eso dicen: no hay más que ver cómo razona o1. En pocas palabras, cada vez la inteligencia industrial se parece mas al cerebro de una persona en cuanto a capacidad y funcionamiento, si proporcionadamente será cuestión de tiempo que lo supere.
Sin bloqueo y desde un punto de paisaje más mundano y práctico, además ha llovido mucho desde ese despliegue generalizado: nuevas versiones de GPT como GPT -4 o GPT-40, la arribada de Gemini de Google como mayor prototipo de la competencia de ChatGPT, entre otros. Y si acostumbras a usar la IA, sabrás que sus resultados se han ido depurando y mejorando, que cada vez es más rápida y admite más formatos (la preeminencia de lo multimodal), la conexión a internet... y hace auténticas maravillas si sabes qué prompt escribirle.
Pero encima hay trucos para conseguir mejores resultados. Porque como las personas, la IA funciona mejor si apelamos a las emociones. La inteligencia industrial va camino de ser cada vez más humana y conforme más experimentamos con ella, más lo constatamos.
La velocidad de procesamiento es una útil esencial en las personas: es la que nos ayuda a entender lo que nos llega de fuera y ofrecer una respuesta cuanto antaño, sirva como ejemplo cuando nos toca musitar con cualquiera que no acento nuestro idioma o cuando nos dan las vueltas tras una transacción. Pero efectuar contrarreloj no siempre es lo mejor. Aunque puede entrenarse, todo el mundo razona mejor cuando nos dan tiempo para pensar.
Pues proporcionadamente, con la inteligencia industrial pasa lo mismo y da igual que estemos hablando de un maniquí de OpenAI que de Google: con más tiempo ofrecen mejores resultados. Sin ir más allá, el novísimo y aún en escalón experiemental Gemini 2.0 Flash Thinking mejora frente a la versión estándar al designar tiempo de inferencia a razonar.
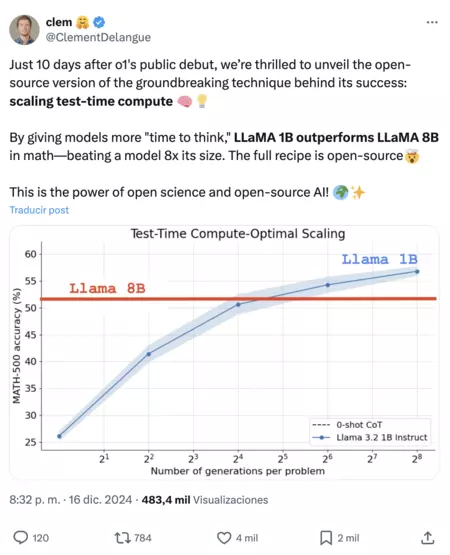
Toca para ir a la publicación de X/Twitter
Lo que ves sobre estas líneas es la diferencia de rendimiento entre LLaMA 1B frente a LLaMA 8B en pruebas de matemáticas pese a que este extremo es notablemente más conspicuo (8x): el secreto está en darles tiempo para pensar, o lo que es lo mismo, ascender el tiempo de prueba de la computación. Y mucho más: Llama 3.2 3B también supera el desempeño de Llama 3.1 70B Instruct, pese a ser este extremo 22 veces más conspicuo simplemente haciendo un escalado inmejorable del cálculo.
Más allá de la curiosidad del descubrimiento, esto es esencial ya que pone encima de la mesa la posibilidad de envidiar con parámetro para optimizar el rendimiento de un maniquí más allá de añadir más capacidad y lo que ello supone. En pocas palabras: los modelos más pequeños, más livianos y asequibles, suben de nivel notablemente ajustando proporcionadamente el tiempo de cálculo.
Portada | Microsoft Copilot Designer con IA
En Genbeta | Los trucos que siempre funcionan para que ChatGPT te dé las mejores respuestas
Compartir este artículo
Consultoria Personalizada
¡Si aun no tienes presencia en internet o
necesitas ayuda con tus proyectos, por favor, escribenos!
En ARTDEPARTMENT nos especializamos en brindar soluciones para que tu negocio, empresa o proyecto sea visible en internet.